Cadre juridique de la protection des données pour le développement et l’utilisation de systèmes d’IA dans les institutions sociales
Rédigé par la Fondation Metaverse Europe avec l’aimable assistance de l’équipe de protection des données du cabinet Gleiss Lutz.
L’intelligence artificielle (IA) offre aux institutions sociales de nombreuses possibilités d’améliorer l’efficacité des processus de travail, de mieux adapter les offres de soutien individuel ou d’optimiser les processus administratifs. Un exemple possible est un système d’alerte précoce pour la mise en danger des enfants : une institution sociale dispose de rapports anonymes sur les évaluations de risque. Une IA évalue ces rapports et assiste les professionnels en leur donnant un « troisième avis » sur l’évaluation des risques dans les nouveaux cas. L’IA peut également générer des cas fictifs sur lesquels les nouveaux professionnels peuvent être formés.
L’utilisation de systèmes d’IA repose généralement sur de vastes bases de données, qui contiennent souvent des informations personnelles. Cela place la législation sur la protection des données au centre des préoccupations.
Le règlement général sur la protection des données (RGPD) constitue le cadre juridique obligatoire pour le traitement de ces données. Il oblige les organisations sociales à respecter un certain nombre d’exigences spécifiques lors du développement et de l’utilisation de systèmes d’IA. Ce livre blanc offre un aperçu pratique des principales exigences en matière de protection des données auxquelles les organisations doivent se conformer dans le cadre du développement et du déploiement de systèmes d’IA.
[1] La présentation détaillée de ces exigences légales spécifiques n’est pas l’objet de ce livre blanc, qui ne vise qu’à fournir un premier aperçu. Toutefois, le contenu de ces exigences est si similaire que les exigences du RGPD peuvent également servir de guide pour les entités qui sont soumises à d’autres régimes juridiques en plus ou à la place.
Clarification de la responsabilité en matière de protection des données
Lorsque les institutions souhaitent utiliser des systèmes d’IA, une question centrale doit être posée au début de toute réflexion sur la protection des données : Qui est responsable, au regard de la protection des données, du traitement des données effectué lors du développement et/ou du déploiement du système d’IA ? Cette clarification est bien plus qu’une simple formalité – elle constitue la base de toutes les autres considérations relatives à la protection des données. En effet, ce n’est que lorsqu’il est clairement établi si un acteur agit en tant que responsable, sous-traitant ou, le cas échéant, en tant que responsable conjoint, que les obligations et exigences applicables peuvent être déterminées en toute sécurité juridique.
Le RGPD établit une distinction fondamentale entre le « responsable du traitement » et le « sous-traitant ». Le responsable est l’entité qui décide des finalités et des moyens du traitement des données à caractère personnel. Il est le destinataire central de toutes les obligations en matière de protection des données. Il doit respecter toutes les exigences matérielles en matière de protection des données et être en mesure de démontrer qu’une protection technique et organisationnelle des données adaptée au risque a été mise en œuvre. Le sous-traitant, quant à lui, agit exclusivement sur ordre et selon les instructions du responsable du traitement, c’est-à-dire précisément pas selon des finalités déterminées par lui-même.
Dans la pratique, cela signifie que si une institution exploite un système d’IA uniquement pour ses propres besoins sur ses propres serveurs, elle est généralement la seule responsable. Toutefois, il est plus fréquent que plusieurs parties collaborent, par exemple lorsqu’une institution utilise un système d’IA d’un fournisseur externe en tant que solution en nuage hébergée par ce fournisseur. L’institution est alors le responsable, tandis que le fournisseur agit généralement en tant que sous-traitant. Dans de telles situations, il est important de conclure un accord de sous-traitance qui définit clairement les droits et obligations de chacun.
Si les fournisseurs de systèmes d’IA utilisent les données collectées dans le cadre de l’application non seulement pour le compte de tiers, mais aussi à leurs propres fins, par exemple pour développer leurs systèmes d’IA, il peut y avoir ce que l’on appelle une « responsabilité conjointe ». Cela signifie que les deux parties décident ensemble des finalités et des moyens du traitement des données et sont donc conjointement responsables du respect des exigences en matière de protection des données. Ce type de situation requiert un accord contractuel transparent entre les parties concernées, dans lequel les compétences, les obligations d’information et les responsabilités sont clairement définies.
Trouver la base juridique pertinente
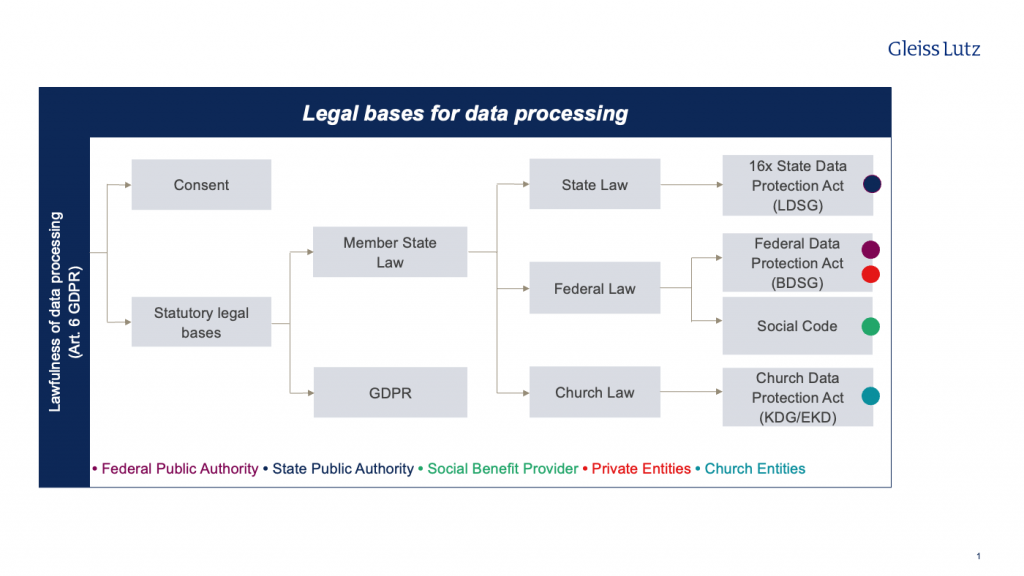
Une fois que les responsabilités en matière de protection des données ont été clarifiées, les responsables doivent réfléchir aux bases juridiques pertinentes. En effet, le traitement de données personnelles (telles que les noms ou adresses et les données liées à une personne par de tels « identifiants ») n’est autorisé que si une base juridique le permet, c’est-à-dire si la personne concernée a donné son consentement ou si une disposition légale autorise le traitement des données.
Le développement et l’entraînement d’un modèle d’IA peuvent généralement être effectués à l’aide de données anonymes. De telles données ne sont pas soumises à la législation sur la protection des données et leur utilisation ne nécessite donc pas d’autorisation au titre de la législation sur la protection des données. Mais attention : selon les autorités de contrôle, le processus d’anonymisation constitue également un traitement de données à caractère personnel, qui nécessite donc une base juridique. Différentes bases juridiques peuvent être envisagées pour différents acteurs, en fonction de la situation :
Entités privées: Intérêt légitime (article 6, paragraphe 1, point f) du RGPD) ;
Organismes publics: Intérêt public (article 6, paragraphe 1, point e), du RGPD en liaison avec la base juridique fédérale ou régionale) ;
Prestataire de services (par exemple, pour les services d’aide à l’enfance et à la jeunesse) : Base légale de protection des données sociales requise.
En cas de traitement de données sensibles (santé, génétique, sexualité, appartenance religieuse, convictions philosophiques, opinions politiques, etc.), une exception doit être prévue par l’article 9, paragraphe 2 du RGPD. Dans la mesure où aucune disposition légale spéciale n’intervient, seul un consentement explicite (article 9, paragraphe 2, point a) du RGPD) entre généralement en ligne de compte comme base juridique possible, mais il est pratiquement impossible de l’obtenir.
Une base juridique est également nécessaire pour le traitement des données à caractère personnel en tant qu' »intrant » d’un système d’IA . Pour trouver la base juridique pertinente, il convient ici aussi de distinguer selon le responsable du traitement qui utilise le système d’IA dans un cas concret. Si le système d’IA est utilisé pour optimiser une tâche existante, il est généralement possible de recourir à la base juridique qui légitime le traitement des données dans le cadre de l’exécution de cette tâche (sans IA) pour le traitement des données à caractère personnel en tant qu' »intrant » du système d’IA. En effet, l’utilisation de certains moyens techniques ou d’un logiciel spécifique pour le même traitement ne nécessite pas de base juridique spécifique.
Le graphique ci-dessous illustre les différentes bases juridiques – selon le type d’entité traitant les données – qui peuvent être prises en considération pour le traitement des données à caractère personnel :
Interdiction des décisions individuelles automatisées
Lorsque des données à caractère personnel sont traitées par un système d’IA, il convient de veiller tout particulièrement à ce qu’aucune décision individuelle automatisée non autorisée ne soit prise. Il s’agit de décisions prises par le système d’IA seul , sans intervention humaine significative, et qui sont susceptibles d’avoir un impact significatif sur la personne concernée. Cela peut être le cas, par exemple, lorsque des prestations sont refusées ou que d’autres mesures défavorables sont prises.
Les décisions automatisées sont en principe interdites. Le RGPD prévoit toutefois certaines exceptions clairement définies dans lesquelles elles peuvent être autorisées. Une décision automatisée n’est autorisée que si elle est nécessaire à la conclusion ou à l’exécution d’un contrat, si elle est expressément autorisée par une disposition légale ou si la personne concernée a expressément donné son consentement. Les exigences sont particulièrement strictes lorsque des données à caractère personnel sensibles, telles que des données relatives à la santé, sont traitées : Dans ces cas, il doit y avoir soit un consentement explicite de la personne concernée, soit une base juridique spécifique prévue par la loi dans un intérêt public important. Les deux cas étant (jusqu’à présent) très rares, il est difficile de mettre en œuvre des décisions automatisées basées sur des données à caractère personnel sensibles dans le respect de la loi.
Afin d’éviter des décisions automatisées non autorisées, il convient donc, avant d’utiliser un système d’IA, d’évaluer précisément si, dans le cas d’application concerné, il peut y avoir un préjudice pour les personnes concernées.
Si tel est le cas, il faut s’assurer que ce n’est pas le système d’IA qui prend la décision, mais un être humain. Et pas seulement sur la forme, mais aussi sur le fond : l’être humain doit prendre la décision de manière autonome, sur la base des faits disponibles et en tenant compte de toutes les exigences légales – et non pas en étant influencé par le résultat ou la proposition du système d’IA.
Pour que cela soit possible, il faut des procédures claires et documentées qui garantissent que les décideurs humains examinent et décident avec le même soin que sans l’aide de l’IA. La contribution du système d’IA doit uniquement permettre d’améliorer la qualité des décisions ou de les accélérer dans le temps, mais ne doit pas les anticiper.
Obligations d’information
Conformément au RGPD, les responsables de la protection des données sont tenus d’informer les personnes concernées de manière exhaustive sur le traitement de leurs données à caractère personnel lorsqu’ils collectent les données auprès de la personne concernée elle-même ou auprès d’une autre source. L’obligation d’information porte notamment sur l’étendue, les finalités, les bases juridiques et la durée du traitement des données, ainsi que sur les droits dont dispose la personne concernée en vertu du RGPD.
Toutefois, la simple utilisation d’un système d’IA n’entraîne pas automatiquement de nouvelles obligations d’information en vertu du RGPD. Le système d’IA ne peut être qu’un outil technique pour une activité de traitement existante, comparable à tout autre logiciel utilisé pour traiter des données. Les institutions ne doivent donc pas, du seul fait qu’elles utilisent l’IA, fournir des informations supplémentaires aux personnes concernées en matière de protection des données.
La situation est différente lorsque des données à caractère personnel initialement collectées pour une finalité spécifique (par exemple, l’exécution d’une tâche particulière) sont désormais traitées à des fins de développement de l’IA. En effet, dans ce cas, la finalité du traitement change. Les institutions sont alors tenues d’informer les personnes concernées de cette nouvelle finalité de traitement.
Des obligations d’information supplémentaires peuvent survenir lorsque le système d’IA prend des décisions individuelles automatisées. Dans de tels cas, le responsable doit informer la personne concernée qu’une prise de décision automatisée est en cours, lui fournir des informations pertinentes sur la logique impliquée et lui expliquer la portée et les effets escomptés du traitement.
Il n’est toutefois pas nécessaire de divulguer les détails techniques ou l’algorithme exact. Il s’agit plutôt de décrire la procédure et les principes de manière à ce que la personne concernée puisse comprendre comment ses données ont été utilisées dans le cadre de la décision automatisée. Les informations doivent être claires, transparentes et faciles à comprendre afin que la personne concernée puisse comprendre la décision et son fondement.
Droits des personnes concernées
Lors du traitement de données à caractère personnel à des fins de développement de l’IA et à l’aide d’un système d’IA, les droits d’accès, de rectification, d’effacement, de limitation du traitement, de portabilité des données et d’opposition despersonnesconcernées doivent être respectés, comme pour tout traitement de données à caractère personnel.
Dans ce contexte, les particularités suivantes apparaissent dans le contexte du développement et de l’utilisation de l’IA :
Si la personne concernée demande des informations sur une prise de décision automatisée, elle doit recevoir, le cas échéant, des informations pertinentes sur la logique impliquée ainsi que sur la portée et les effets escomptés d’un tel traitement. Le responsable du traitement doit donc être en mesure d’expliquer de manière compréhensible et transparente le fonctionnement et les principales procédures du système d’IA utilisé, de sorte que la personne concernée puisse comprendre comment et pourquoi la décision a été prise sur la base de ses données à caractère personnel. Pour ce faire, le responsable du traitement doit, le cas échéant, se faire accorder lui-même des droits d’information vis-à-vis d’un fournisseur d’IA tiers, afin que le système d’IA ne constitue pas pour lui une « boîte noire ».
Lorsque des données à caractère personnel font partie d’un modèle d’IA, la correction ou la suppression de ces données implique généralement des efforts techniques et organisationnels considérables. C’est notamment pour cette raison qu’il est recommandé d’utiliser des données anonymisées pour développer des modèles d’IA.
Dans la mesure où le développement d’un modèle d’IA est fondé sur un intérêt légitime, les personnes concernées ont le droit de s’opposer au traitement. La mesure dans laquelle le responsable peut démontrer des intérêts impérieux et rejeter l’opposition dépend du cas d’espèce.
Réalisation d’une analyse d’impact sur la protection des données
Lorsque les institutions utilisent un système d’IA qui traite des données à caractère personnel, il est souvent nécessaire de réaliser une analyse d’impact sur la protection des données (AIPD) au préalable. En effet, une telle évaluation est obligatoire, en particulier lorsque de nouvelles technologies sont utilisées et qu’elles sont susceptibles de présenter un risque élevé pour les personnes concernées. Les autorités de contrôle de la protection des données estiment que c’est précisément le cas lorsque des systèmes d’intelligence artificielle traitant des données à caractère personnel sont utilisés.
L’objectif de la DSFA est d’identifier à un stade précoce les risques pour les droits et libertés des personnes concernées et de prendre les mesures de protection appropriées. La DSFA est donc une procédure structurée qui permet au responsable de prendre conscience de l’impact que peut avoir le traitement de données envisagé.
Un DSFA devrait au moins inclure les points suivants :
Description du traitement : quelles données doivent être traitées et à quelles fins ? Quels sont les intérêts poursuivis par le responsable du traitement ?
Évaluation de la nécessité : le traitement à cette échelle et de cette manière est-il réellement nécessaire pour atteindre les objectifs poursuivis ?
Évaluation des risques : quels sont les risques pour les personnes concernées ?
Mesures de réduction des risques : quelles sont les mesures de protection techniques et organisationnelles prévues pour réduire ou éliminer ces risques ?
Autres obligations du responsable
L’utilisation de systèmes d’IA peut entraîner le transfert de données à caractère personnel vers des pays situés en dehors de l’Union européenne ou de l’Espace économique européen . C’est notamment le cas lorsque des fournisseurs ou prestataires de services non européens sont impliqués dans le développement ou l’exploitation du système d’IA.
Dans ce cas, il convient de vérifier si une décision d’adéquation de la Commission européenne s’applique au destinataire des données (par exemple pour le Canada, le Japon, la Corée du Sud). Si ce n’est pas le cas, il est possible de conclure ce que l’on appelle des clauses contractuelles types. Il faut toutefois tenir compte du fait que dans certains domaines, notamment publics, des règles plus strictes s’appliquent, qui interdisent expressément le transfert vers des pays tiers sans décision d’adéquation.
Si le développement ou l’utilisation d’un système d’IA entraîne des modifications dans les activités de traitement du responsable du traitement, celles-ci doivent en outre être reflétées en conséquence dans le registre des traitements.
Résumé
L’utilisation de l’IA dans les institutions sociales offre un grand potentiel d’amélioration des processus et d’optimisation des services de soutien individuels. Parallèlement, le traitement des données à caractère personnel dans le cadre de systèmes d’IA pose de nombreux défis en matière de protection des données. Les institutions responsables doivent donc examiner attentivement la manière dont elles peuvent se conformer aux exigences du RGPD. Des responsabilités claires, le choix de la bonne base juridique, le respect de l’interdiction des décisions individuelles automatisées et la transparence vis-à-vis des personnes concernées sont des facteurs clés de succès.
L’aperçu ci-dessous résume les principales mesures à prendre en compte pour une utilisation de l’IA conforme à la protection des données :
No.
To-Do
1
Clarifier les responsabilités Qui est le responsable de la protection des données ? Y a-t-il un seul ou plusieurs responsables de la protection des données ? Des sous-traitants sont-ils utilisés ?
2
Trouver la base juridique Quelle est la base juridique pertinente pour le traitement des données à caractère personnel ?
3
Respecter l’interdiction des décisions individuelles automatisées Des décisions individuelles automatisées sont-elles prises par/avec l’aide du système d’IA ? Cela est-il autorisé à titre exceptionnel ?
4
Respecter les obligations d’information Les personnes concernées doivent-elles être informées séparément du traitement de leurs données à caractère personnel ? Si oui, comment s’en assurer ?
5
Satisfaire les droits des personnes concernées Comment garantir les droits des personnes concernées, notamment les droits d’accès, d’effacement et d’opposition ?
6
Analyse d’impact sur la protection des données Une analyse d’impact sur la protection des données doit-elle être réalisée ?
7
Transfert international de données Y a-t-il un transfert de données personnelles en dehors de l’UE ? Si oui, comment le respect des exigences légales en matière de protection des données est-il assuré ?
8
Compléter le registre de traitement Le traitement des données à caractère personnel est-il déjà représenté dans le registre de traitement ou doit-il être complété ?
Un témoignage et un regard vers l’avenir L’année dernière, nous avons développé et testé deux prototypes innovants en collaboration avec la KJSH Kinder Jugend und Soziale Hilfen. L’objectif était d’explorer de manière pratique l’utilisation de l’intelligence artificielle et de la réalité virtuelle dans le domaine de l’aide à l’enfance et à la jeunesse et d’acquérir une première expérience solide. Dans […]
Renforcer la qualité des décisions grâce à l’intelligence des données et à la formation immersive Les professionnels des institutions sociales sont confrontés quotidiennement à des situations décisionnelles sensibles : Mise en danger du bien-être de l’enfant, besoin de soins imminent, crises dans les groupes de vie. La base de données à cet effet est riche – documentation de cas, données […]
Inspiré par Yoshua Bengio. Poursuivi par des partenaires de la Fondation Metaverse Europe et des experts « Je n’aurais jamais pensé que l’IA deviendrait aussi puissante aussi rapidement – et je m’inquiète de ce qui pourrait arriver si nous ne la gérions pas intelligemment ». Ces mots d’avertissement sont de Yoshua Bengio, l’un des pères du deep learning et lauréat […]
Que signifie encore aujourd’hui être « allemand », « européen » – ou « libre » ? Dans un monde où l’interdépendance mondiale, l’accélération technologique et les structures de pouvoir économique imprègnent tous les aspects de la vie, il devient de plus en plus difficile de répondre à cette question. Les États-nations perdent de leur influence, tandis que le capital, les algorithmes et les marchés mondiaux […]
Le mercredi 26 mars 2025, nous nous sommes réunis dans la salle du conseil d’administration du Berlin Capital Club pour mon premier « AI Talk » en compagnie de personnalités de haut niveau. Eberhard Schnebel, philosophe, économiste et théologien, professeur d’éthique économique à l’université Goethe de Francfort, membre du conseil d’administration d’EBEN GR (European Business Ethics Network – Greek Chapter) […]
Le coup d’envoi de la métaphore éducative Le 30 octobre 2024, le coup d’envoi de la nouvelle initiative éducative Metaverse de la fondation Metaverse Europe a été donné au gameslab de l’université Humboldt à Berlin. Cette initiative a pour objectif d’intégrer durablement les technologies immersives et l’intelligence artificielle dans le domaine de l’éducation afin de créer des espaces d’apprentissage personnalisés […]